Sift - Outlier Detection: Difference between revisions
| Line 15: | Line 15: | ||
The points o1 and o2 in the picture above both represent outliers. Some algorithms may not classify o2 as an outlier, as it has a similar density to the points in C1, but we see that based on the local tendencies of the data, it should be classified as an outlier. | The points o1 and o2 in the picture above both represent outliers. Some algorithms may not classify o2 as an outlier, as it has a similar density to the points in C1, but we see that based on the local tendencies of the data, it should be classified as an outlier. | ||
The LOF is a statistic calculated for each point in the database, with values below 1 representing inliers (as they are in a denser neighbourhood than their k neighbours), while outliers are determined based on a threshold above 1, which should be tuned depending on the data being used. For more information on the implementation and guidelines for using this method, see the [[Sift Tutorial: Outlier Detection#Local Outlier Factor|LOF section of our PCA Outlier Detection Tutorial]]. | |||
====Algorithm==== | ====Algorithm==== | ||
Revision as of 12:54, 3 May 2024
| Language: | English • français • italiano • português • español |
|---|
Outlier Detection is encompassed in a variety of statistical methods which look to find data that is not representative of dataset to which it belongs. These outliers (or anomalies) may then be further analyzed, or simply discarded. There are a variety of different methods to do this, including supervised and unsupervised methods. Here we will describe some common detection methods, all of which have been implemented into Sift. Specifically, these methods are used to detect outliers using PCA Workspace Scores, the scores obtained by applying the PCA Loading vectors onto the original waveforms.
Unsupervised Methods
Local Outlier Factor
Local Outlier Factor (LOF) is an unsupervised method of finding outliers through a data points local density, introduced in 2000 by Breunig et al. [[1]]. It compares the local density of each point to its local neighbours, and calculates a Local Outlier Factor as the average ratio between its own density and the neighbours. By doing so, it can find local outliers that a global method might not find.

The points o1 and o2 in the picture above both represent outliers. Some algorithms may not classify o2 as an outlier, as it has a similar density to the points in C1, but we see that based on the local tendencies of the data, it should be classified as an outlier.
The LOF is a statistic calculated for each point in the database, with values below 1 representing inliers (as they are in a denser neighbourhood than their k neighbours), while outliers are determined based on a threshold above 1, which should be tuned depending on the data being used. For more information on the implementation and guidelines for using this method, see the LOF section of our PCA Outlier Detection Tutorial.
Algorithm
- Calculate the k-nearest neighbours:
- Using a distance metric (such as Euclidean Distance), calculate the k nearest neighbours for all data points.
- Calculate reachability distance:
- For each point, calculate the reachability distance between itself and its k neighbours, defined as the maximum of:
- The distance between the 2 points.
- The distance from the neighbouring point to its own k-th nearest neighbour (known as the k-distance of the neighbouring point)
- Note that the use of reachability distance helps to normalize or smooth the output, by reducing the effects of random fluctuations (i.e. random points that are extremely close together)
- The reachability distance from p1 to o, and p2 to o is shown below:

- For each point, calculate the reachability distance between itself and its k neighbours, defined as the maximum of:
- Calculate local reachability density:
- For each point, the local reachability density is 1 / (the average reachability distance to the k nearest neighbours), i.e.:
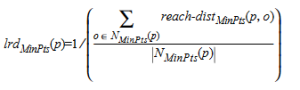
- Calculate local outlier factor:
- For each point, the local outlier factor is the average ratio between the points local reachability distance and each of the local reachability distance of the k nearest neighbours, i.e.

- Threshold to find outliers:
- Identify a threshold for which to determine points are outliers. This threshold should be some point above 1 (as a LOF of > 1 represents lower density than its neighbours), and should be done as a case by case basis. An automated method to choose a threshold is to use an iterated one-sided Grubbs outlier test on the LOF values, to determine outliers with a significance level alpha.



Grubbs' Outlier Test
The Grubbs' Outlier test is a method of finding a univariate outlier in normally distributed data. The test statistic represents the largest deviation from the sample mean (in terms of the standard deviation), and is compared against a t-distribution representing the stated significance level. The statistic is calculated as follows (for a one sided-maximal value test):

The null hypothesis of no outliers is rejected (at significance level a) if (i.e. we identify the maximal value as an outlier):

If we successfully reject the null hypothesis, we remove the outlier from the data, and calculate the statistic again on the new data. We can continue this until no outliers are detected, or stop after X outliers have been identified (X being up to the user).
Reference
- Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng, and Jörg Sander. 2000. LOF: identifying density-based local outliers. SIGMOD Rec. 29, 2 (June 2000), 93–104. https://doi.org/10.1145/335191.335388
- Abstract
- For many KDD applications, such as detecting criminal activities in E-commerce, finding the rare instances or the outliers, can be more interesting than finding the common patterns. Existing work in outlier detection regards being an outlier as a binary property. In this paper, we contend that for many scenarios, it is more meaningful to assign to each object a degree of being an outlier. This degree is called the local outlier factor (LOF) of an object. It is local in that the degree depends on how isolated the object is with respect to the surrounding neighborhood. We give a detailed formal analysis showing that LOF enjoys many desirable properties. Using real-world datasets, we demonstrate that LOF can be used to find outliers which appear to be meaningful, but can otherwise not be identified with existing approaches. Finally, a careful performance evaluation of our algorithm confirms we show that our approach of finding local outliers can be practical.